

In a contemporary social milieu riddled with technical “jargon” that can seem as impenetrable as it is omnipresent, what do terms like “metadata” mean in a practical sense to the “average” concerned citizen? What are some “accessible,” practical ways that someone without prior expertise in technology can take precautions to protect their metadata? Why does it matter?
Introduction:
Shortly over a decade ago, Harlo Holmes, the current (2025) Director of Freedom of the Press Foundation and FPF Digital Security Officer, gave an excellent lecture for the Deep Lab Lecture Series’ STUDIO for CREATIVE Inquiry Series on the topic of “activist metadata.” Holmes uses the term “activist metadata” to describe how metadata can be “mobilized” (no pun intended) in the service of governmental surveillance and in resisting surveillance. Speaking in her capacity as a regular contributor to The Guardian Project, a nonprofit dedicated to protecting the digital rights and security of activists, journalists, and humanitarians, Holmes discusses her work with WITNESS, The International Bar Association, Open News, Deep Lab, and “the computer-assisted reporting team” at The New York Times, (sponsored by Mozilla Foundation and the Knight Foundation). In particular, Holmes discusses the specific apps that she helped design and develop in her work in these organizations — apps that use specific strategies of documenting metadata (information regarding the context of a digital file (format, when and where the file was made/uploaded/downloaded, etc.)).
Holmes’ work has contributed to making “easy to use secure apps, open-source software libraries, and customized mobile devices that can be used around the world by any person looking to protect their communications and personal data from unjust intrusion, interception and monitoring [x].” In doing so, Holmes’ inventions enact a tactical use of metadata that takes the same information archiving and extraction tools that can be used to exploit or spy on vulnerable people by turning these strategies back on oppressive state powers.
What struck me about Holmes’ lecture when I encountered it as a young graduate student, only a few months prior to Trump’s first election, was not a sense of dread spurred on by my hyper-awareness of a surveillance state that I was already exhausted by to the point of near-apathy. Rather, I was struck by the hope I felt at the possibilities offered by “tech theory” as manifested in Holmes and her colleagues’ work. The idea of developing actual technology utilizing the very mechanisms of control so often employed for exploitation in service of self-protection offered a potential bridge between the seeming “abstraction” of “tech theory” with principles of design and practice involved in the development and application of usable tech.
Holmes’ work is theoretically indebted to theories of surveillance/sousveillance specifically developed in Black feminist digital studies. In her multi-award-winning Dark Matters: On the Surveillance of Blackness (2016), Dr. Simone Browne describes the concept of “sousveillance” — the use of surveillance technologies that can and have been used by oppressed groups, particularly Black people, in service of resistance. “Sur” is French for “above” and “sous” is French for “below.” Thus, if “surveillance” is observation from “above,” then “sousveillance” suggests looking up from “below.” The term, as Browne uses it, works to (re)situate Foucauldian notions of “pan-opticonism” in the context of a “white gaze” of surveillance to account for how anti-Black surveillance techniques can and have been “appropriated, co-opted, repurposed, and challenged” by Black subjects” in order to facilitate survival and escape” (Dark Matters 21).1 Holmes’ formative lecture was — and remains — an example of how concepts explored in Dr. Browne’s scholarship on Blackness and sousveillance, going back to the history of trans-Atlantic slavery to the present TSA system, can be employed in practice and in praxis. I still believe that to be true today.
Yet today, writing in 2025, I am also struck by how so many of the sinister catalysts that sparked Holmes’ lecture not only remain relevant, but have grown exponentially more malignant. Holmes and her Deep Lab colleagues’ goals are more pertinent than ever in our contemporary social zeitgeist not despite the drastic technological development over the past decade, but because of it. While I could not more highly recommend checking out Holmes’ lecture on your own time, if you are reading this blog post, you are probably here in part because you are curious as to what metadata is and why it matters in a political and social context as I write in April 2025. In fact, you may still be curious about these questions reading much, much later.
If this post survives.
So let’s start with the basics: What is metadata? Why does it matter? Why, in particular, given how the overwhelming cultural atmosphere right now screams The Center Cannot Hold and Mere Anarchy Is Unleashed Upon the World, does considering metadata in the context of advocacy and activism even matter? And, if it matters, how do we address these issues in a practical way?
In the following blog post, I will attempt to cover the concept of “metadata” and privacy in a manner accessible to audiences interested in the topic without assuming any prior familiarity with the subject from the reader. I end with several educational resources and privacy/safety suggestions.
What is Metadata?
The term “data” means “information.” “Meta” in this context means “referring to itself or to the conventions of its genre; self-referential” by the Merriam-Webster dictionary. The term “meta” in English comes from the Greek word “meta” as “beyond,” “after,” or “behind.” The original Greek usage of the term “meta” still has connotations and usage in some English words with Greek roots; for example, “metaphysics” (“beyond” empirical physics) or or “metacommentary” (commentary beyond or after a specific text). For this blog post, however, “metadata” is essentially “information about information.” All digital files have metadata. (Technically, so do analog files, but that is another topic for another conversation). Digital files can include PDFs, screenshots and other photographs, videos, folders, downloads, etc. The more “complicated” the file type, the more metadata can be extracted from the file.
For example, the following image shows a screenshot saved on my computer that I took of a lesson plan introduction for a lesson I wrote during my tenure as a staff member for the Digital Writing and Research Lab, when I was responsible for producing digital pedagogy resources for the lab as a graduate student researcher.1
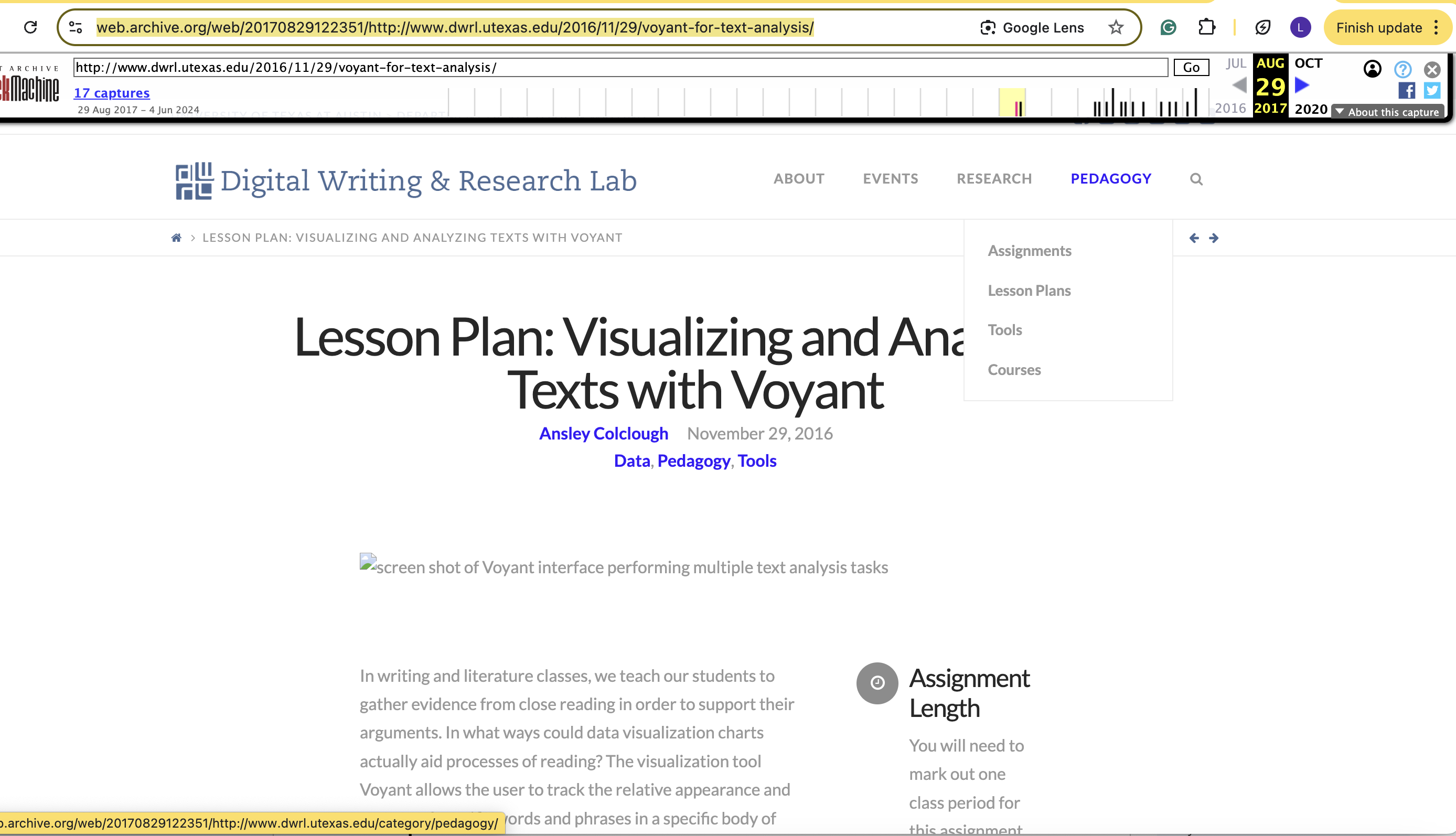
Image: Screenshot of Internet Archive Wayback Machine record of Lesson Plan. Source: Lior Colclough
This screenshot can be understood as a piece of “information” in the most general sense that knowledge can be gleaned from encountering this image (noting, of course, that gleaning knowledge and verifying reputability or accuracy are not the same practice). Examples of such information include:
- Text
- Visuals
- Interface design
- Publication date (as recorded by screenshot)
- Other visual representations on the JPG file itself of what this interface looked like at a specific moment in time at a specific url.
Metadata is “information about information,” which means information regarding the context through which the screenshot came into existence and the context of the other information. This context includes information about the item itself and how/when/where the file was produced in both digital and non-digital “space.” Examples of metadata that can be discovered from a screenshot include:
- Date/time of the screenshot’s capture
- Technology/Operating System
- IP address (in some cases)
- File format
- History of file format conversion (in some cases)
In this case, this particular screenshot was taken at 2025–02–22 at 11.14.05 Am. The format is a jpg. While I could probably see what IP address I was using at the time, I use a VPN so often that I hardly even remember what my most frequent IPs are and I am too lazy to track it down for this particular blog post. (I tentatively plan to write a post on the benefits and limitations of using a VPN in the future. I may “bump up” that topic in my “to write” list upon request if there is demand). My point in offering this example is to distinguish between data as “information” and “metadata as information about information” by offering the most simplistic example that came to my mind.

A screenshot is a very simple digital file. More complicated files and formats will have and require more forms of metadata. For a more complex example, during an academic calendar-long research project that I conducted in graduate school funded by the DWRL Flash Fellowship project, I embarked upon a digital archiving and data visualization project that used data visualization and sentiment analysis tools to perform a diachronic and synchronic analysis of the changing contexts of the word “bot” in The New York Times over the course of several decades. Although I was able to automate immediate tagging using the software platform, I was forced to manually enter other metadata elements for the hundreds of individual articles I uploaded to the now-defunct platform Overviewdocs. These metadata elements included author, publication date, column/genre, etc., or any other information that I could not reliably trust the platform to label correctly in a way that would be beneficial to the type of analysis that I needed. One reason I had to manually add certain meta categories was that Overview did not automatically and accurately “label” each article I uploaded as I needed for my project. For some reason, the publication date was difficult for the software platform to recognize easily due to the text format of the PDF copies of the articles.
Another reason I had to manually add or look over automated metadata (as always when using automated technology) was to “fact-check” specific categories and topics for accurate qualitative context. For example, during the 2016 peak popularity of the musical Hamilton, numerous articles about bots and ticket-scalping appeared in The New York Times prior to the 2016 election, at which point the conversation around bots shifted to political misinformation. Thus tags such as “Hamilton,” “ticket-scalping,” etc. were relevant to archive and document the context surrounding a particular stretch of news coverage on bots. However, if the author of an article had the surname “Hamilton,” or another person or place with that surname appeared in the article, then Overviewdocs could falsely “flag” that article under a specific tag if I relied only upon keyword searches and recognition. Therefore, it was necessary to comb through each automated tag on a case-by-case level in order to verify context and topic in order to guarantee accurate results. Although the file formats for each individual article was relatively simple (I used PDFs for ease of access or converted CSV files as needed for larger folders), the metadata elements that I measured in this project included both quantitative and (manually verified) qualitative factors in each file that were necessary for my particular project.

Other forms of metadata that may be relevant for understanding the context of a file could also include:
- Download date
- Original upload time to a particular website
- File conversion history, etc.
For my Flash Fellowship archiving project, I did not record these elements on the platform itself, as they were A) not relevant to what I wanted to research and (more importantly, given the specific platform I chose to use) B) could easily clutter up my results with too many tags. Of course, another researcher who wished to verify my description of my project methods could have looked up the download dates/location/etc. of my original copies. However, as I was not studying the download date/file type/etc but other metadata elements, these were not the metadata elements I prioritized when labeling and uploading files.
The bottom line: as these files and this project were more complex and layered than a simple screenshot, the processes through which I extracted and, at times, manually labeled metadata or fact-checked the automated labels, were more complicated in part because the project goal was more complicated. There are multiple ways to extract, label, and identify metadata elements depending upon the digital file(s) being analyzed and for what purpose.
In short, when we say that “metadata” is “information about information,” this means (simplified) that metadata provides contextual information about a digital file as a “text.” “Text” here does not simply refer to “words” or even coding, SEO data, etc. alone, but “text” in the literary analysis sense of “an object that can be analyzed in whatever way.” With this definition in mind, let’s move on to the reason that we’re all here: why does this distinction matter legally (and by extension) practically?
How Can Metadata Be Weaponized For or Against Oppression?
How a government can use metadata in the service of surveillance should not be difficult to parse. Nonetheless, while I am sure many of you reading this post are aware that data and metadata can be accessed by law enforcement through dubious legal means, the extent to which this occurs and how may be unfamiliar to you. Or, for those who are familiar, the sheer scope of information and resources may seem overwhelming.
For starters, the police can access your phone metadata even during times in which your phone is turned off or on airplane mode. For example, after the 2022 murders of four University of Idaho students, police filed a search warrant for Bryan Kohberger, the suspect ultimately indicted with those murders, using cellphone data that verified the presence of the phone within the vicinity of the murders near the estimated time of the crime despite the fact Kohberger (allegedly) had the phone turned off at the time. I bring this up not to dabble in true crime “speculation” regarding the guilt or innocence of Kohberger. I bring up this publicly available information as a mere example demonstrating that law enforcement can access data regarding your phone’s location at a specific time even if the phone is turned off.
Now, you may personally believe that Kohberger is guilty or innocent or have different feelings regarding the legality of a phone company handing over such information either in response to a subpoena or willingly. That is beside the point. For regardless of how you may feel about Bryan Kohberger, in a political climate riddled with mass deportation (especially for dissidents) of legal residents following a long documented history of non-violent protesters or even bystanders being mistreated and/or framed by the police, I do not think it particularly radical to note that even those who may feel you have “done nothing wrong” — and legitimately done nothing illegal (or amoral) — ought to take pause and consider how “innocence” in the eyes of the law has never dissuaded punishment in the grip of authority.
Therefore, do not bring your phone to a nonviolent civil disobedience demonstration. Do not TURN IT OFF. LEAVE IT AT HOME. The same goes for any wearable devices (Apple Watches, Fitbit, etc.).
I realize that for those with mobility issues who rely on their phone for transportation and others who need electronic aids for other reasons, this may be difficult. Try to carpool if you can or arrange alternate means of transportation. If this is not possible, then consider other ways to support dissent. For instance, look into bail fund advocacy in your community. There are other ways that you can participate — here are some suggestions at this open source Google Doc — but do not under any circumstances bring your cell phone to a protest or anything else that has access to the internet or collects data.
Another important thing to keep in mind is that the police do not need a warrant to order you to open your phone with facial recognition or fingerprint. The police do require a warrant to open your phone with a passcode. So for this reason….
Disable all facial recognition/finger print recognition on your phone and other electronic devices and set up a passcode.
In addition to educating yourself on your rights and on proper conduct with the police (tl;dr: don’t say anything except “Am I detained?” and “I would like to see a lawyer”), know that while the cops can and will lie to you about the law, that they cannot make you unlock your phone with a passcode without a warrant. For devices that have the option of nondigital activation such as door locks, cameras, your refrigerator, etc. absolutely find the most “lo-tech” access option possible (more on this principle in a later blog entry). This includes your laptop. For a cellphone, however, a passcode is probably the best that can be done and can easily be done by anyone who owns one.
So What Next?
So, what does this (very rudimentary) overview of what metadata “is” mean in terms of creating an actionable agenda? For starters, even if you do not consider yourself an “activist” or have any plans to participate in civil disobedience at this time, it is worth considering how information about your information can be accessed not only by authorities, but by corporations who could misuse your data at worse or, at best, sell your data in other ways that may lead to other complications that may be as trivial as spam inundation and search engine “filter bubbles” — the later of which is hardly “trivial” at all.
Going forward, it is worth understanding not only how what you access online and how you use your phone data but also the when/where/what format/WHO of your data usage can be accessed in ways that may be out of your control. In Holmes’ lecture at the beginning of this blog entry — which I still recommend — Holmes notes the potential of self-documenting metadata for providing an alibi for those falsely accused of wrongdoing. Such methods only succeed in a justice system that cares about delineating punishment based on right or wrong. Given that even “exonerating” circumstances seem to mean little for achieving clemency, as the story of Kilmar Ábrego García starkly illuminates, even those who feel they “have done nothing wrong” or “have nothing to hide” ought to consider thinking about information and privacy with a nuanced understanding of what information can be accessed and how in order to take pragmatic precautions.
Digital Advocacy Resources:
EFF – Media Tips for Activist Groups
Activist Checklist.org – Prepare for a Protest
The Activist Handbook: Campaigning Guides for Activists
Harlo Holmes “Everything You Wanted to Know About Media Metadata You Were Afraid to Ask,” Freedom of the Press Foundation
See Also:
See also: Dr. Simone Browne Subverting Surveillance: Strategies to End State Violence Conference.
This screenshot covers the webpage interface on 29 August 2017 looks like on The Wayback Machine. Unfortunately, due to apparent technical difficulties in reformatting the DWRL website (that occurred after I moved on to a different academic appointment), the original link to my lesson plan is no longer supported by the website format, thus forcing me to use the Wayback version to authenticate the original publication.
↩︎

Leave a comment